
This article provides a holistic view of the Chainlink Data Feeds, focusing on security. The article targets mainly EVM and Solidity and has three main parts:
- Architecture of the feeds and off-chain aggregation protocol
- Trust model
- Common data-feed-related issues
Firstly, we introduce the problems Chainlink solves and how they solve them: the core idea of the off-chain aggregation protocol is explained, and the core contracts are described. Then we discuss the trust model of the feeds. This will help you evaluate how risky it is for you to integrate the feeds into your protocol. Lastly, and most importantly, we discuss the data-feed-related issues: we provide explanations, code examples, and recommendations on how to avoid the issues.
Architecture & Off-chain aggregation
Motivation
During the execution of a smart contract, we can’t call external APIs as we need deterministic execution for all the nodes. As such, it is problematic to access off-chain data from smart contracts. Thus, we need EOAs to post the data to the chain.
We need three things for posting off-chain data to the chain:
- independence and quality of the off-chain data feeds
- decentralization of the entities that post the data to the chain
- freshness of the data
Chainlink tries to achieve this via its off-chain aggregation protocol (OCR).
Off-chain reporting protocol
OCR is a protocol built around a decentralized oracle network, which is a network of (hopefully) independent nodes. The nodes monitor multiple off-chain feeds to get information about current prices. As part of OCR, a leader is selected. The leader aggregates reports from other participants and then sends a transaction to the chain.
If the leader misbehaves, he gets slashed. The report is sent to the Chainlink contracts. There the report is read, signatures are verified, and the median of the prices is taken:
int192 median = r.observations[r.observations.length/2];
require(minAnswer <= median && median <= maxAnswer, "median is out of min-max range");
r.hotVars.latestAggregatorRoundId++;
s_transmissions[r.hotVars.latestAggregatorRoundId] =
Transmission(median, uint64(block.timestamp));Architecture of the Data Feed contracts
Each feed (e.g., BTC/ETH, ETH/USD,..) has two main corresponding contracts – a proxy and an aggregator. If you copy a data feed address from the Chainlink dashboard, you get the address of the Proxy. The Proxy then points to the implementation – the aggregator.
Here is a diagram from the docs:
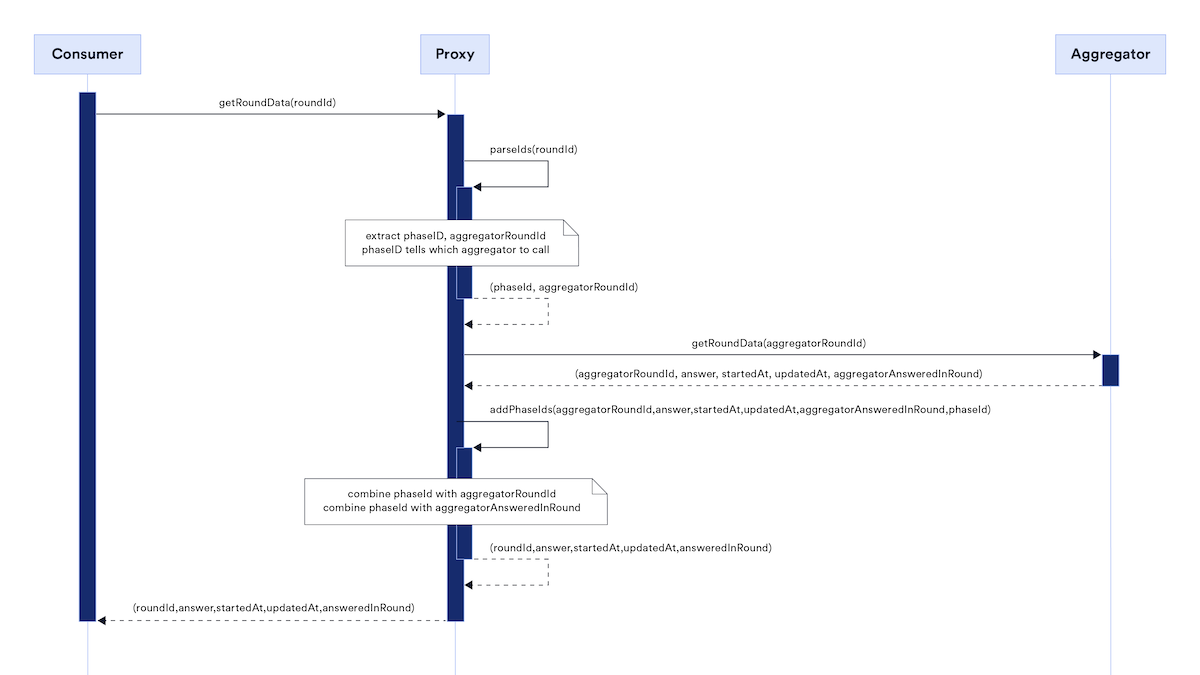
The Proxy allows for the protocol to be upgradeable. The aggregator then handles all the reporting logic.
Proxy
For the consumer contracts, the Proxy exposes the AggregatorV3Interface. This allows the consumers to retrieve the prices and additional metadata.
It also allows for upgrading the aggregator contract (the access controls are mentioned in the Trust model). During each upgrade, a phaseId variable is incremented. Using the phases, we can query even historical aggregators and, thus, historical data.
Aggregator
The AccessControlledOffchainAggregator is the contract that handles the price updates. The prices are updated in two scenarios:
- heartbeat threshold triggers (the data feeds are updated periodically)
- deviation threshold triggers (off-chain values deviate by at least the threshold value and thus must be updated)
One price update defines one round. With each update, we increment roundId variable. Each update takes block.timestamp and sets it as the time of the update of the feed. This timestamp is the value that is returned as startedAt, updatedAt when calling latestRoundData().
AggregatorV3Interface
Most protocols will interact with the Data Feeds using the AggregatorV3Interface. The API is well described in the docs. We will specifically focus only on latestRoundData() function.
function latestRoundData() external view
returns (
uint80 roundId,
int256 answer,
uint256 startedAt,
uint256 updatedAt,
uint80 answeredInRound
)The roundId and answeredInRound contain the same value which is the latest round as it was described previously. answer is the price and startedAt and updatedAt again contain the same value and correspond to the round’s timestamp as described previously.
It can be surprising that the variables contain the same values, see the code for a proof. The same values are returned because the aggregators were upgraded, but Chainlink kept the API (i.e., previous versions behaved differently).
We even wrote a test to verify this:
#eth mainnet addrs
feeds = {
"usdt/eth" : Address("0xEe9F2375b4bdF6387aa8265dD4FB8F16512A1d46"),
"usdc/eth" : Address("0x986b5E1e1755e3C2440e960477f25201B0a8bbD4"),
"btc/eth" : Address("0xdeb288F737066589598e9214E782fa5A8eD689e8"),
"eth/btc" : Address("0xAc559F25B1619171CbC396a50854A3240b6A4e99"),
"eth/usd" : Address("0x5f4eC3Df9cbd43714FE2740f5E3616155c5b8419"),
"ampl/usd" : Address("0xe20CA8D7546932360e37E9D72c1a47334af57706"),
"matic/usd" : Address("0x7bAC85A8a13A4BcD8abb3eB7d6b4d632c5a57676"),
"ftm/eth" : Address("0x2DE7E4a9488488e0058B95854CC2f7955B35dC9b"),
}
@default_chain.connect(fork=" https://eth-mainnet.g.alchemy.com/v2/top_secret")
def test_get_data():
for type, addr in feeds.items():
roundId, answer, startedAt, updatedAt, answeredInRound = AggregatorV3Interface(addr).latestRoundData()
assert roundId == answeredInRound
assert startedAt == updatedAtThe last important thing to discuss here is the decimals. Each pair has decimals representing the decimals (as we know them from eg, ERC20) of the price. Some feeds have 8 decimals, and some 18. There is not a clear rule on how many decimals each data feed has; see the following list of decimals of pairs we retrieved from mainnet:
feed usdt/eth, decimals: 18 feed usdc/eth, decimals: 18 feed btc/eth, decimals: 18 feed eth/btc, decimals: 8 feed eth/usd, decimals: 8 feed ampl/usd, decimals: 18 feed matic/usd, decimals: 8 feed ftm/eth, decimals: 18
The feeds denominated in ETH seem to have 18 decimals and feeds denominated in non-ETH have 8 decimals. However, at the same time we have the AMPL/USD feed which has 18 decimals, which breaks the rule.
Trust model
This section will discuss the trust assumptions the protocols and security researchers have to consider when interacting with the Data Feeds.
First and foremost, the Data Feeds are upgradeable. A Chainlink-operated multisig owns the Proxy contract of each feed. They use a Safe multig, which we found by extracting the owner address from the Proxy and inspecting it on Etherscan. The multisig has 9 owners and its threshold is 4, see the contract on evm.storage. That means that only 4 signatures are needed to update any of the feeds arbitrarily.
Each upgrade can fail or can incorporate censorship of specific addresses.
Additionally, the nodes of the OCR protocol have to be trusted. They are supposedly decentralized and independent, but their count is much lower than the count of Ethereum nodes, so manipulation could be easier.
Also, even the Data Feeds can provide incorrect values even if the nodes are honest. This happened in the past, see the post-mortem.
Issues
In this part, we will describe all the issues that can arise when interacting with the Data Feeds. We will mainly focus on the newest V3 version.
1. Deprecated API
Some of the functions that the Data Feed contracts expose are deprecated and shouldn’t be used anymore. See the full list. Those functions can be removed in future upgrades and thus aren’t safe to use.
These functions are:
- getAnswer,
- getTimestamp,
- importantly latestAnswer,
- latestRound,
- latestTimestamp.
2. Receiving stale data
Each Data Feed can return stale data, e.g., due to a bug in an upgrade, OCR nodes not being able to come to consensus, etc. However, the AggregatorV3Interface provides enough information to check whether the data is fresh.
One of the values that the latestRoundData function returns is updatedAt. Additionally, we have access to block.timestamp. We get the time since the last update by subtracting these two values. We can set a maximal threshold that this difference can be. If it is greater, the data is stale, and we revert.
3. Too wide freshness interval
As we explained in the previous issue, we need staleness checks. However, if we use too wide freshness threshold, then we won’t be able to detect stale prices in time.
The interval mustn’t be too wide. Ideally, it should be relative to the heartbeat interval of the given feed.
4. Too narrow freshness interval
Additionally, we can’t decide to use a very narrow freshness interval. If it was decided for a freshness interval shorter then the heartbeat period, then some of the queries of the feeds would incorrectly revert. As a result, the user would be DoSed.
5. Reading prices inside try/catch block
As we explained, the contracts are upgradeable, and thus the calls can revert due to a bug or censorship. In such cases, the protocol can get stuck, and the users DoSed.
If we read the prices using try/catch we can recover from the revert and, for example, try a different oracle, e.g. TWAP.
6. L2 sequencer downtime
On some L2s (like Arbitrum or Optimism), we have an entity called a sequencer. The sequencer is a node that receives users’ transactions and posts them in a batch to the L1. Currently, almost no protocol provides decentralized sequencing, and thus their downtime is relatively possible.
At the same time, these L2s provide an option to interact with them directly through the L1 contracts without requiring the sequencer intervention.
Chainlink provides a feed to check the sequencer downtime, which should be updated through the L1; see the docs.
Additionally, Chainlink updates the L2 Data Feeds through the sequencer, so if it is down, the prices aren’t updated.
We haven’t found conclusive proof on this, but it is heavily implied by the fact that Chainlink itself recommends in the docs to check the sequencer uptime when querying the data feeds. If the data feeds weren’t updated through the sequencer, this recommendation wouldn’t be present.
Suppose that the sequencer is offline, but the users can bypass it and send their transaction directly through L1. Additionally, suppose that a protocol integrates the ETH/USD feed and that the price of ETH drops heavily. A malicious user sees this and sends a transaction through the L1 contracts. The transaction is processed in the context of prices that were not yet updated, and thus, the user is benefiting from the still-high prices.
See a more detailed blog post about this issue.
7. Hardcoded Data Feed addresses
Using hardcoded data feed addresses is dangerous as, nowadays, the contracts are being deployed on multiple chains. On different chains, the feeds can have different addresses.
The protocol can use invalid feed addresses if the source code isn’t modified for each deployment.
8. Wrong interpretation of decimals
Some feeds have 8 decimals, some 18, and there is no clear rule on how many decimals each feed has. It is necessary to either query the decimals function of the given feed or retrieve the information before deployment.
It shouldn’t be assumed that a given feed has x decimals without first verifying it. Using wrong assumptions about decimals can lead to serious accounting errors.
9. Backup oracle
If a call to the feed reverts (e.g., after a failed upgrade), having a backup oracle (like a TWAP) will allow the protocol to continue operating without DoSing the users.
As auditors, we should carefully verify the backup oracles, as the corresponding logic can be undertested, as their usage can be assumed as a low-likelihood scenario.
10. Low-quality feed
Not all feeds are created equal. Some might be lower quality or can have deprecated status. Luckily, Chainlink provides status for each of the feeds. It is recommended to verify the status of the feed before using it.
11. Basic price validation
A large number of protocols use the following require for validating the price: require(answer > 0, “invalid price”);. This way, a basic sanity check of the price can be implemented. Protocols can add additional requirements that the price lies in some sane <min, max> interval, which could be used to avoid using the protocol during sudden price crashes (e.g. deppegging).
Conclusion
Chainlink oracles are the most widely used oracles. They have shown great reliability, but the protocol isn’t fully decentralized and has several trust assumptions.
Protocols that integrate the oracles can encounter various issues, such as using deprecated API or insufficient price data validation.
Read more of our research here.


